[TOC]
1、来解决一个问题
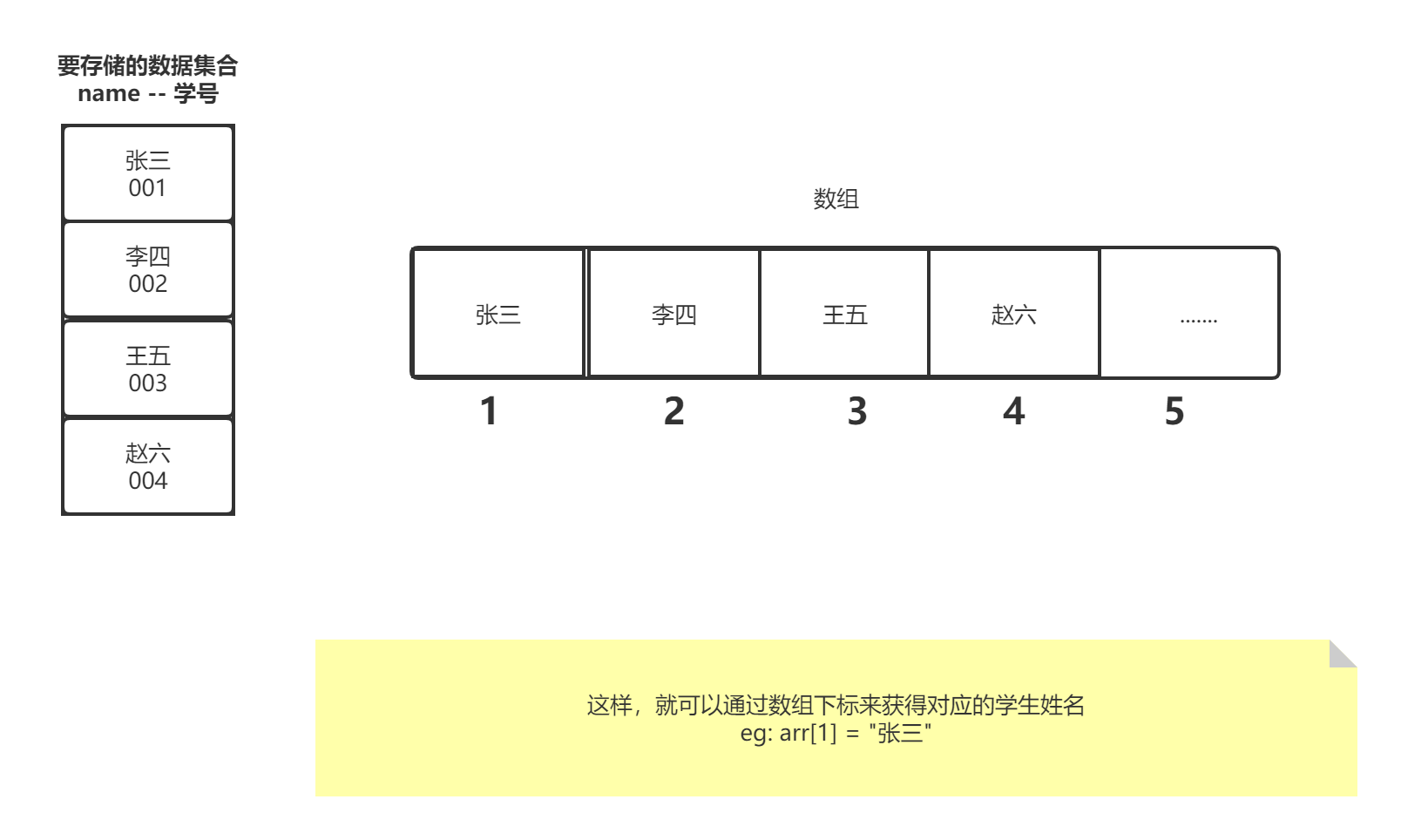
Q:给定一组学生数据,数据格式为学号-学生姓名;现在要求:输入学生的学号,能够快速查询出学生的姓名。
A:如何解决上面的问题?思路有如下:
- 遍历,直接暴力遍历,直到找到学生姓名
- 使用哈希表,通过哈希表的
key-value映射来查找
- 使用数组下标映射的关系,通过将id作为学生下标来存储学生姓名。
2、位图
通过上面的问题,我们知道可以通过一 一映射的关系来进行数据快速存储查询。
**==位图:==**位图位图,就是只存储一位(0/1),通过0/1来判断true/false
Q:现在又有一个问题,假设有100万个整数,整数范围为0~3千万。问:如何快速确定某个数据是否在这100万个数据中?
A:来思考下如何解决,常见方案如下:
① 基于数组: 这种方式的话就要直接暴力遍历,伪代码如下:
1
2
3
| for(int i = 0;i < nums.length;i++){
if(nums[i] == target)return i;
}
|
② 基于排序数组:这种方式是对上面方法的改进,通过排序后可以进行二分查找,提高查找效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Arrays.sort(nums);// 进行排序
// 二分查找伪代码
boolean binarySearch_r(int[] nums,int left,int right,target){
while(left <= right){
int mid = left+(right-left)/2;
if(nums[mid] == target)return true;
if(nums[mid] < target){
binarySearch_r(nums,mid+1,right);
}else{
binarySearch_R(nums,left,mid-1);
}
}
return false;
}
|
③ 基于哈希表:基于哈希表实现的话,维护对应的数值关系即可。
④ 基于一一映射的数组:就是使用数组,将有值的下标标记为true,否则标记为false。
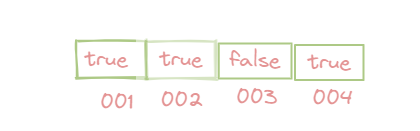
⑤ 基于位图:基于上面方式的话,可以,但是true/false还是很占空间啊

我的需求只是要知道是不是有没有存在这个数而已
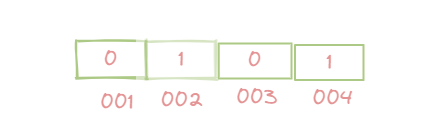
只有想不到没有做不到,我们思考一下能不能直接用0/1来存储每一位上的值。
实际上是可以的,通过使用char类型的数组,char是16个字节,64位,每位来保存对应的数据。
赋值:a[charIdx] |= (1<<bitIdx)
取值:a[charIdx] & (1<<bitIdx)
让每位的0/1表示有没有这个值
3、布隆过滤器
接着上面题目进行延伸,假设有1000万个整数,整数范围为0~1亿。问:如何快速确定某个数据是否在这1000万个数据中?
如果要接着使用位图的话,就要存储相当大的存储空间了。
但是我们转念一想,如果使用位图,并且对应的下标为哈希计算之后的值,这样可以减少存储空间。
只是,这样的话就很容易导致哈希冲突,也就是两次计算之后的值是一样的。
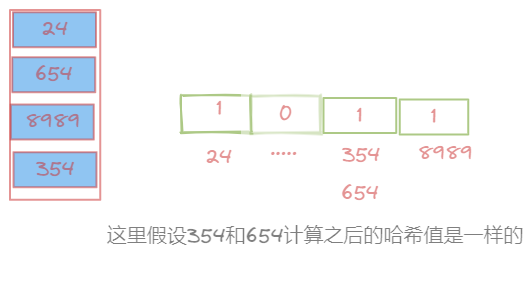
所谓的布隆过滤器,其实就是位图+容忍存在hash冲突的误判
我们假设使用上面图中的布隆过滤器判断某个值是否存在,如果存在的话例如:hash(354) == 1,hash(654) == 1,而hash(200) 肯定是0
这样的话,就算存在哈希冲突,也造不成多大的关系。
4、布隆过滤器的常见使用
通过使用布隆过滤器,我们可以快速地知道某个值是否存在数据中,大大提高查询速度。
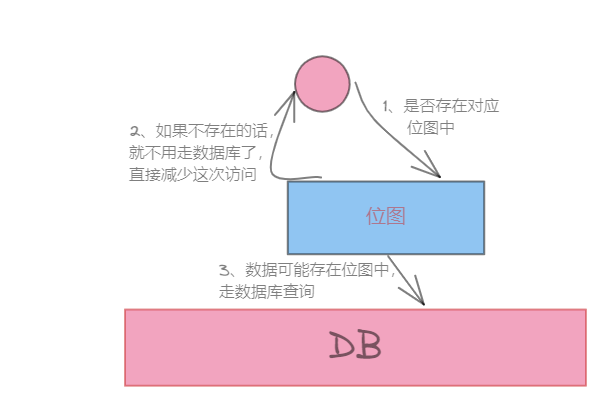
比如,在判断某个数据是否存mysql中时,先访问缓存中的位图判断是否存在,如果数据压根不存在mysql中的话,就不用走库区查询了,减少数据库的操作。
总结
1、通过对数组对了解,我们知道数组的下标可以得到更好的利用
2、位图采用更少的空间消耗来存储数据,实现数据和一些业务目的一一映射
3、布隆过滤器是“粗糙版”的位图,通过布隆过滤器可以实现海量数据下的数据是否存在判断