如何给20G大小的成绩文件进行排序
[TOC]
如何给20G大小的高考成绩文件进行排序?
这个问题很值得思考,每年高考/考研之后,几百甚至几千万考生的成绩,如何才能排好序呢?这是个值得思考的问题,这篇文章来进行一波分析。
一 问题分析
- 问题的要求是对给定的一份20G的成绩文件进行排序,不存在说文件内存在其他特殊字符之类的异常数据。
- 进行排序的环境不确定,可能是单机(在一台机器上完成)、也可能是多机集群同时进行处理。
- 单机的内存是有限的,假设每台机器的内存只有3GB。
- 排完序后要求得到一份排好序的文件。
- 假设磁盘不低于50GB。
二 单机情况下的处理
1、首先由于内存有限,没有办法一次性将所有20GB的文件都读取到内存中。
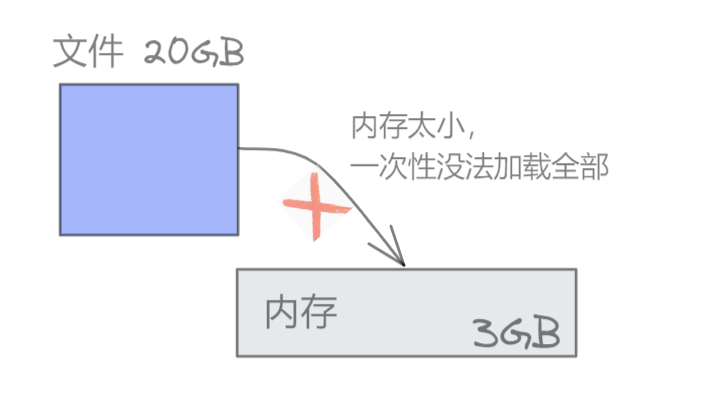
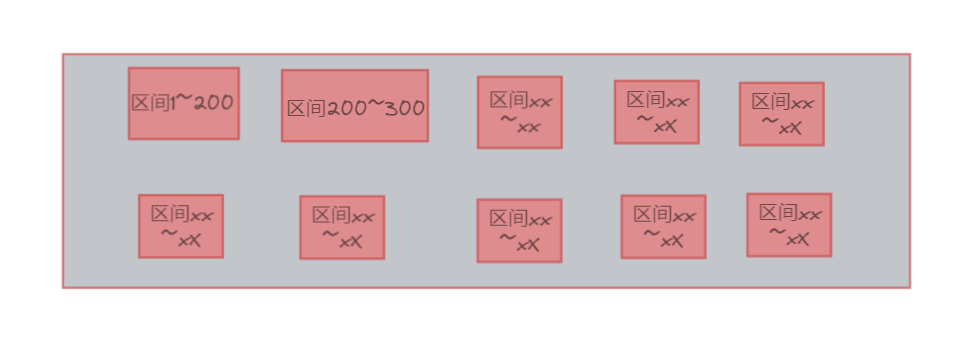
2、所以考虑每次只加载2G到内存中,为了保证数据区间能够均匀地分布,采用哈希分片将文件分批读取到内存
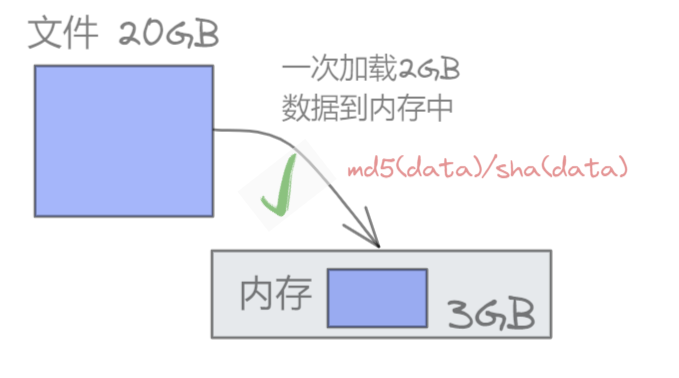
为什么每次不加载3G呢?
注意,内存总量为3GB,如果将3GB都用来放成绩数据,其他程序和数据就没地放了。
3、对内存中的数据进行排序(使用堆排序/快速排序或者Tim排序)
4、将排好序的内容单独生成一个文件,放到硬盘上
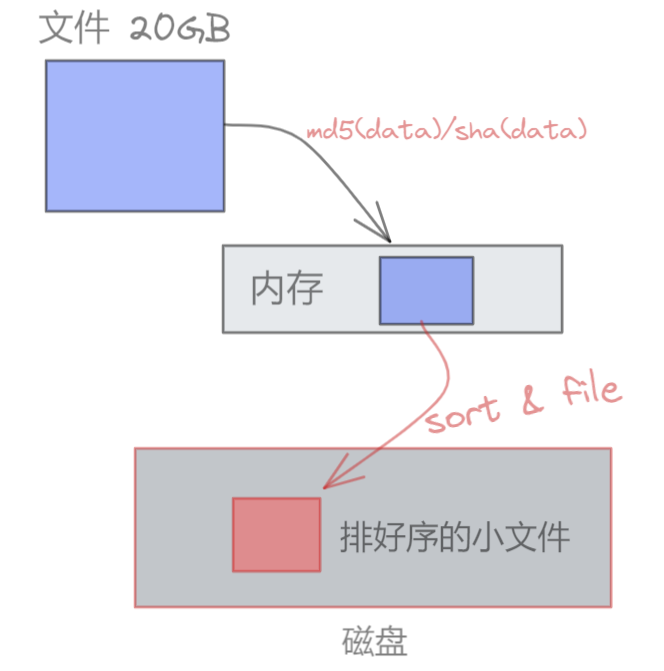
5、继续重复将剩下的18G数据按照①、②、③、④步骤进行处理,处理10次之后,此时硬盘上有10份排完序的成绩小文件
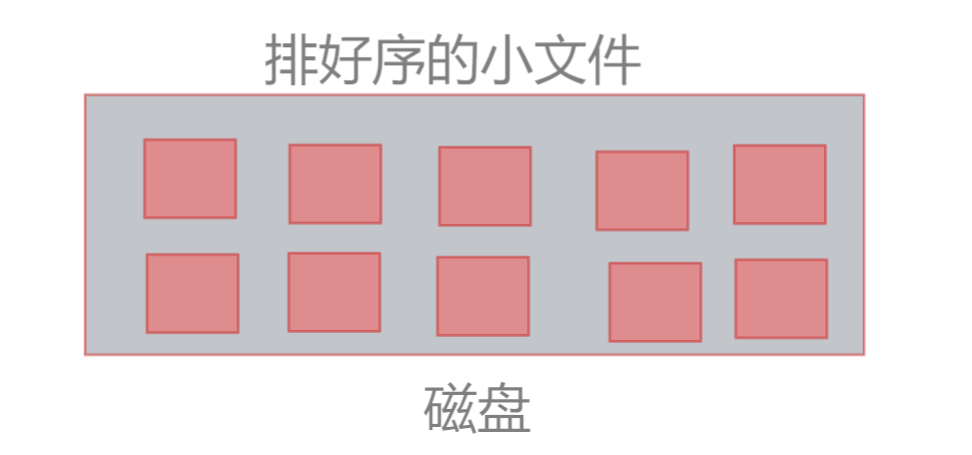
6、将这10份排好序的小文件合并成一份大文件
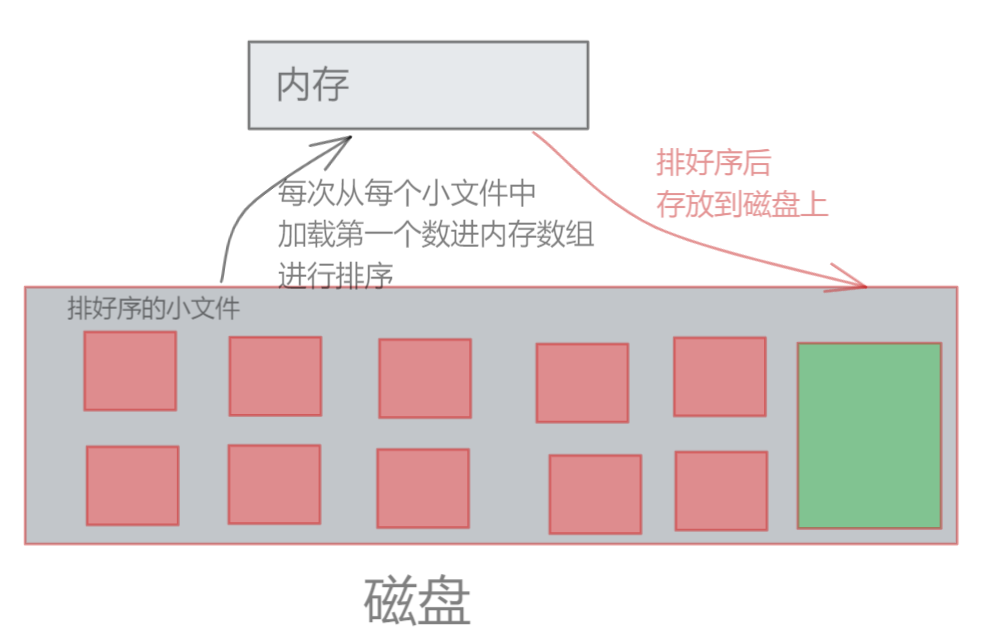
首先创建一个大小为10的数组,然后依次从10个文件中找出第一个数,写到原来文件中(直至最终排序完成)
(由于前面有将数据进行哈希分片,所以数据区间是均匀的,能够保证每个文件的第一个数值是这段区间内的最小值/最大值,而且不会存在于其他区间上)
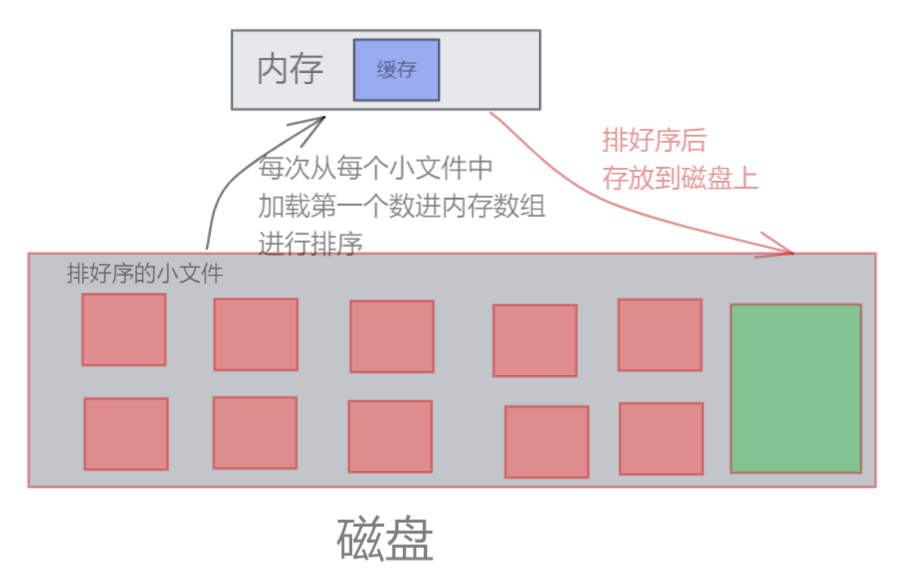
7、由于每次只从文件中读取一行效率太低了,可以考虑给每个文件都加一个缓存,每次都读取这个前置缓存中的值,这样效率性能会大大提高。
三 多机集群环境下的处理
多机情况下也是类似的,可以考虑将文件数据均匀放到各个机器上,每个数据都落到对应的数据区间中。
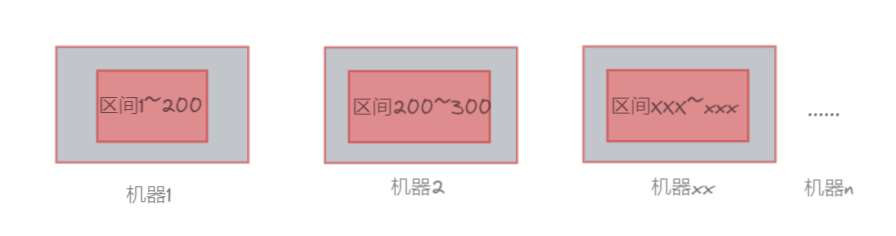
然后进行排序,排完序后有多个有序的小文件,再考虑将这些个小文件给合并成大文件就好了(思路跟单机处理中的大差不差)
四 总结
1、单机情况下由于内存资源限制,只能一步一步对文件进行排序,然后再将小文件合并成大文件。
2、多机情况要好得多,可以一次批量排序多组文件,排序效率会明显提升。
通过上面的学习,你也可以很轻松地对高考后的考生成绩进行排序了。不过好像我们也没有必要操这份心,毕竟我也不想知道我高考或者考研之后的排名 : )